Multi-Chip-Modul Beschleuniger sind nichts Neues. Diese ehemaligen Lösungen gingen auf die Kentsfield- und Yorkfield-Quad-Core-Prozessoren von Intel zurück (Ursprünglich auf dem 65-nm-Prozess für das LGA 775-Socket gebaut). Soweit so gut, doch das Problem mit dieser Art von leistungsfähiger, performanter Zwischenverbindung, ist den verschiedenen Kernen in jedem Modul zu ermöglichen, wirklich „miteinander zu reden“ und somit perfekt zusammenzuarbeiten. In jüngster Zeit hat AMD die Vorteile eines echten MCM (Multi-Chip-Module) -Ansatzes mit seinen Ryzen-CPUs gezeigt. Diese resultieren aus der Entwicklung einer modularen CPU-Architektur mit einer leistungsstarken Interconnect (Infinity Fabric), die es AMD erlaubt hat, die Größe auf ein Minimum zu halten, während es möglich geworden ist bis zu 16 Kerne (2 MCMs) mit Threadripper und 4 MCMs mit Epyc (32 Kerne) zu konstruieren.
AMD hat bereits Hinweise geäußert, dass seine kommende Navi-Architektur ein echtes MCM-Design auf GPUs bringen wird. Vega unterstützt bereits AMDs Infinity Fabric Interconnect und ebnet den Weg für zukünftige APU-Designs des Unternehmens. NVIDIA selbst scheint Fortschritte zu einer MCM-fähigen Zukunft zu machen und den monolithischen Design-Ansatz zu verlassen, den das Unternehmen schon lange betreibt.
NVIDIA glaubt, dass ein modularer Ansatz die beste derzeit technisch und technologisch machbare Lösung für ein stagnierendes Moore-Gesetz sei. CPU und GPU Leistung und Komplexität hat sich stark auf steigende Transistoren konzentriert, deren Entwicklung jedoch Produktionseinsätze verlangsamt. In der Tat wird derzeit geschätzt, dass die größte Größe, die mit der heutigen Technologie erreichbar ist, ~ 800 mm² beträgt . Diese Tatsache, gepaart mit dem ständig wachsenden Bedarf der Branche an immer größerer Leistung, führt uns zu der Annahme, dass die GV100 GPU eine der letzten monolithischen Design-GPUs von NVIDIA sein wird (es gibt noch eine Chance, dass 7-nm-Fertigung dem Unternehmen ein wenig mehr Zeit in der Entwicklung einer echten MCM-Lösung einräumen wird)
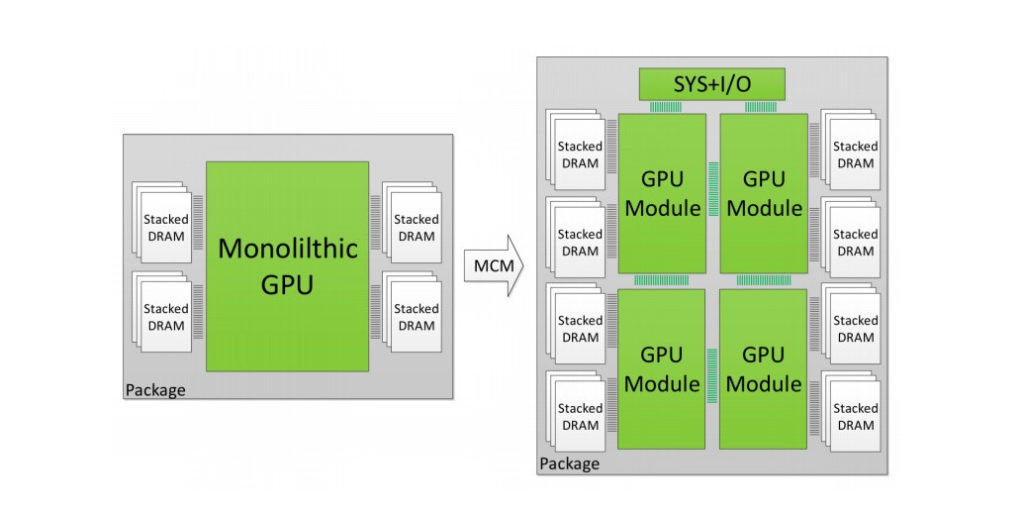
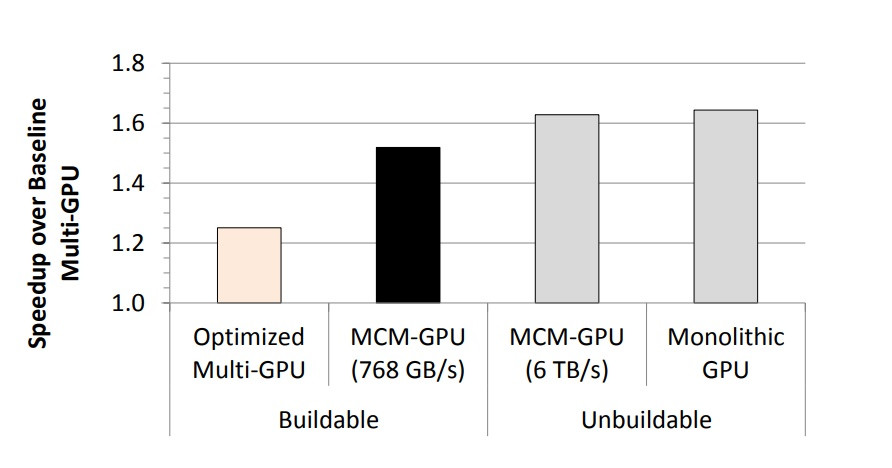
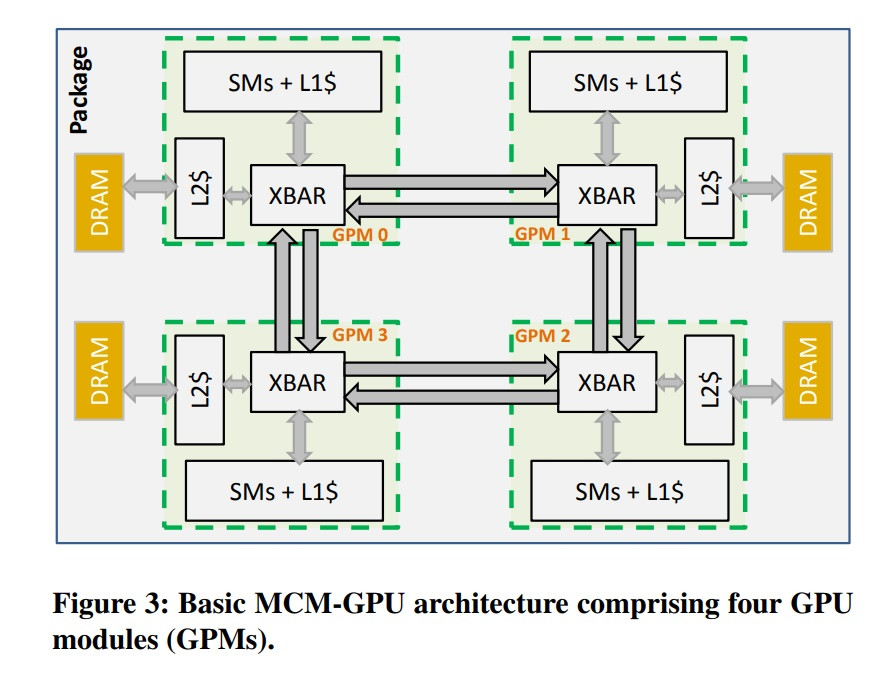
In einem Papier, das von der Firma veröffentlicht wurde, sagt NVIDIA selbst, dass der Weg in die Integration von mehreren GPU-Verarbeitungsmodulen in einem einzigen GPU-Paket der richtige Weg sei, die GPU-Welt zu erreichen, was Ryzen und seine Threadripper und EPYC bereits realisiert haben. NVIDIA äußert sich und stellt klar, dass sie mehrere GPUs in einfach zu erzeugende GPU-Module (GPMs) integrieren und diese mit hoher Bandbreite und leistungsstarken Signalisierungstechnologien ausstatten. In seinem Whitepaper sagt NVIDIA außerdem: „Das optimierte MCM-GPU-Design ist 45,5% schneller als die größte umsetzbare monolithische GPU und 26,8% schneller als ein gleichermaßen ausgestattetes Multi-GPU-System mit der gleichen Gesamtzahl der SMs und DRAM-Bandbreite.“
Diese Entwicklungen zeigen für das Unternehmen sehr vielversprechende Produkte, denn die Aufhebung der monolithischen Designphilosophie und die Skalierung mit einer variablen Anzahl kleinerer Matrizen sollten höhere Erträge und eine verbesserte Leistungsskalierung ermöglichen und damit die hohen Werte beibehalten.
* Bei den mit (*) markierten Links handelt es sich um Affiliate-Links. Von Käufen, die über einen solchen Link durchgeführt werden, erhält HardwareInside eine Provision.
Zuletzt aktualisiert am 13. Januar 2026 um 7:11 . Wir weisen darauf hin, dass sich hier angezeigte Preise inzwischen geändert haben können. Alle Angaben ohne Gewähr.